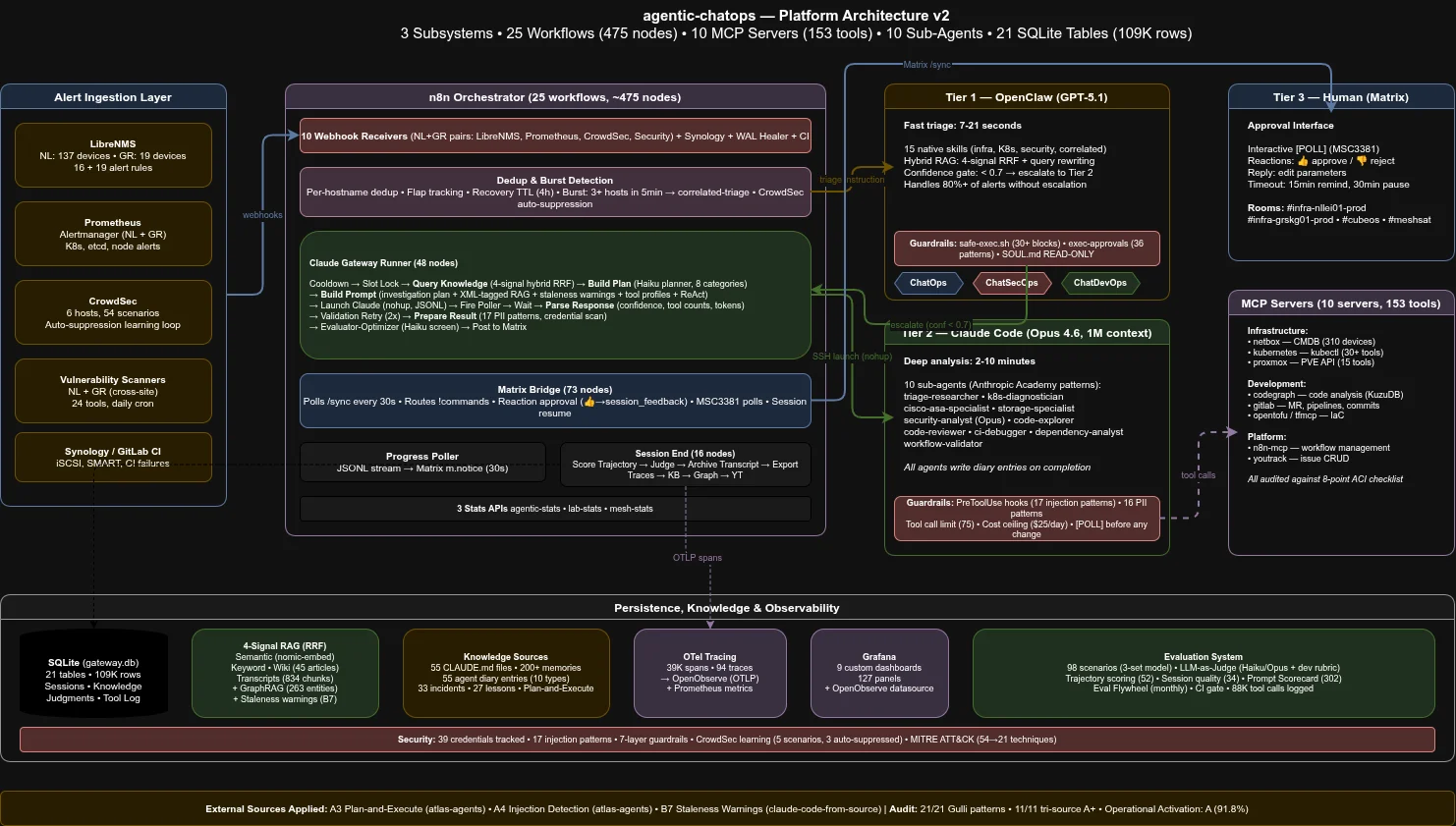
Agentic ChatOps is a production system run by one person across 310+ infrastructure objects and six sites. Three AI subsystems triage alerts, investigate root causes, and propose fixes; a human approves every change. The genuinely novel part is a causal world-model of the infrastructure — a dependency graph that predicts the consequences of a proposed action before it can be approved, then verifies the outcome against that prediction in code. No remediation reaches a human’s approval without a machine-computed prediction attached, and the operator stays ring 0.
One person. 310+ infrastructure objects across 6 sites. 3 firewalls, 13 Kubernetes nodes, self-hosted everything. When an alert fires at 3am, there’s no team to call. There never is. So I built three AI subsystems that handle the detective work — and wait for a thumbs-up before touching anything.
GitHub: papadopouloskyriakos/agentic-chatops
Usage
The auto-resolve rate is intentionally conservative. Autonomy is earned per-action-class through the verification contract — an action type may self-resolve only after its predictions have repeatedly matched observed reality — never switched on globally. A low number here is the safety system working, not a ceiling.
What Makes This Different
Infragraph — a Causal World Model with a Non-Bypassable Prediction Gate
The newest and most distinctive layer. The system maintains a causal dependency graph of the whole infrastructure (716 entities / 607 relationships) seeded daily from five truth layers — live Proxmox cluster API (0.95 confidence), LibreNMS device-dependency parents (0.90), NetBox devices + physical cables (0.85–0.90), operator-declared edges, and a statistical incident-co-occurrence miner deliberately capped at 0.75 — with per-edge dynamics (expected alert cascades, propagation delays, recovery times) learned from 152 chaos experiments and the full triage history.
It is a genuine model-free → model-based shift enforced in control flow, not data — not “a new data source the LLM may query,” but a deterministic predictor the orchestrator calls, whose output is mandatory and machine-verified:
- Prediction is computed outside the LLM — deterministic graph traversal (
infragraph-query.py), invoked by the n8n Runner between Classify Risk and Build Prompt, never at the model’s discretion. - Prediction is mandatory and non-bypassable — the Runner commits a plan-hash-keyed prediction artifact before any approval poll. A remediation proposal without one is rewritten to
[POLL-WITHHELD:NO-PREDICTION]and demoted to analysis-only. The kill-switch (INFRAGRAPH_DISABLED=1) fails the remediation lane closed; the advisory triage-enrichment lane fails open so alert triage never blocks. - Verification is mechanical — after execution, code (never the LLM that proposed the action) diffs observed alerts against the prediction and writes a
match / partial / deviationverdict. Deviation = surprise = never auto-resolve.
The eval is falsifiable by design: every prediction is scored against a degree-preserving shuffled-graph negative control. The canonical 2026-05-11 cascade backtest — the n8n-OOM mass-flap that originally dragged auto-resolve down — was iterated in the open (19.5% → 26.4% → 28.7% → 34.5% coverage / 38.2% escalation coverage / control ratio 0.367 ≤ 0.5×), each round driven by what the misses exposed. Suppression authority is granted per rule by the operator: the system proposes a control issue with an evidence table, the human approves, and closing the issue instantly revokes it. The whole epic (IFRNLLEI01PRD-1029) went from concept to live, operator-approved suppression in a single day. Runbook: docs/runbooks/infragraph.md
.
Self-Improving Prompts — now with A/B trials
The system evaluates its own performance and auto-patches its instructions. Every session is scored by an LLM-as-a-Judge
on 5 quality dimensions — local gemma3:12b via Ollama by default (flipped to local-first on 2026-04-19 after a 60-query calibration against Haiku showed 85% agreement), with Haiku retained for calibration re-runs and flagged sessions re-scored by Opus.
When a dimension trends below threshold, the 2026-04-20 preference-iterating patcher (prompt-patch-trial.py
) generates 3 candidate instruction variants (concise / detailed / examples) per low-scoring dimension — plus a no-patch control arm. Future matching sessions are routed deterministically via BLAKE2b(issue_id || trial_id) % (N+1). A daily cron runs a one-sided Welch t-test once every arm has 15+ samples; the winner is promoted to config/prompt-patches.json only if it beats control by ≥ 0.05 points at p < 0.1. Otherwise the trial aborts and the dimension stays un-patched until the candidate pool is edited. Prompt-level policy iteration — no model weights ever fine-tuned, no wasted patches shipped blind.
AI Planner Wired to 41 Proven Ansible Playbooks
Before Claude Code investigates, a Haiku planner generates a 3-5 step investigation plan. The planner queries AWX for matching Ansible playbooks from 41 proven templates — maintenance windows, cert rotation, K8s drain/restore, PVE kernel updates, DMZ deployments. Plans naturally include “Run AWX Template 64 with dry_run=true” as remediation steps. Inspired by microsoft/sre-agent ’s “Knowledge Base as runbooks” pattern, but using existing Ansible instead of inventing a new format.
Predictive Alerting
Instead of only reacting after alerts fire, the system queries LibreNMS API daily for trending risk across both site instances. Devices are scored on disk usage trends, alert frequency, and health signals. A daily top-10 risk report posts to Matrix before problems become incidents. 123 devices scanned, 23 at elevated risk in the latest run.
5-Signal RAG + GraphRAG + Cross-Encoder Rerank + Staleness Warnings
Retrieval uses Reciprocal Rank Fusion across 5 signals:
- Semantic — nomic-embed-text (768 dims) via Ollama on RTX 3090 Ti, with
search_query:/search_document:asymmetric prefixes - Keyword — hostname, error code, resolution text matching
- Compiled Wiki — 72 articles from 7+ sources, daily recompilation
- Session Transcripts — 838 MemPalace verbatim exchange chunks (weight 0.4)
- Chaos Baselines — chaos experiment results by hostname (weight 0.35)
Plus a GraphRAG + infragraph knowledge graph (716 entities, 607 relationships) for incident→host→alert traversal and machine-computed blast-radius prediction. A dedicated cross-encoder reranker (BAAI/bge-reranker-v2-m3 served at nllei01gpu01:11436, sqrt-blended to handle bimodal scores) reorders the fused results; when its top score falls below 0.7, a cross-chunk synth step (local qwen2.5:7b via Ollama, SYNTH_BACKEND=qwen by default since 2026-04-19) composes an answer from the top 10 fresh candidates — +13pp judge-graded hit@5 on the 50-query hard-retrieval set. An mtime-sort intent detector bypasses semantic retrieval when the query asks for “files created in the last N hours” (satisfied by source_mtime ordering, not cosine similarity). Age-proportional staleness warnings flag results older than 7 days.
Karpathy-Style Knowledge Compilation
Following Andrej Karpathy’s LLM Knowledge Bases pattern
: 7+ raw sources compiled into 72 browsable wiki articles with auto-maintained indexes, contradiction detection, and health checks. The compiler runs daily with SHA-256 incremental hashing. All articles embedded into the RAG pipeline as the 3rd fusion signal. Each row carries a source_mtime column so “what changed in the last 48 hours” queries work as a real retrieval mode.
119K Tool Calls Instrumented with OTel Tracing
Every tool call (119K across 108 types) is logged with name, duration, exit code, and error type. 39K OTel spans exported to OpenObserve (OTLP). OpenObserve added as Grafana datasource (alongside Prometheus + Loki) — all observability in one UI. Per-tool error rates and p50/p95 latency visible in Grafana. 18K infrastructure SSH/kubectl commands tracked across 232 devices. 39 credentials monitored with 90-day rotation policy. Per-source token caps prevent context overflow (incident 4K, wiki 4K, lessons 2K, memory 2K, diary 1.5K, transcript 1.5K).
Hardened RAG Evaluation
The RAGAS golden set was hardened in April 2026 from 18 saturated queries (faithfulness ~0.88 across configs — couldn’t measure pipeline improvements) to 33 queries with 15 hard-eval tagged across 5 categories: multi-hop, temporal, negation, meta, and cross-corpus corroboration. Easy vs hard queries now show a 10× faithfulness differential, so retrieval changes are measurable again. A weekly hard-eval cron (Monday 05:00 UTC) on a 50-query hard-retrieval-v2 set produces judge-graded hit@5 = 0.90 and emits six kb_hard_eval_* Prometheus metrics with absent-guard alerts.
Structured Agentic Substrate — 9 adoptions from the OpenAI Agents SDK
The official openai/openai-agents-python SDK was audited against this system; 9 of 11 surfaced gaps were adopted, turning the old string-based Matrix pipeline into a versioned, typed, recoverable substrate. Best result: a handoff envelope that compresses 176 KB of prior-agent history to 752 B on the wire (0.43% ratio), so escalation no longer re-derives context via RAG.
The nine adoptions
- Schema versioning on 9 session/audit tables + a central registry mirroring the SDK’s
RunState.CURRENT_SCHEMA_VERSION/SCHEMA_VERSION_SUMMARIESpattern. Writer/reader shape drift fails fast instead of silently corrupting replay. - 13 typed events in a new
event_logtable — replaces free-form Matrix strings with Grafana-queryable telemetry. - Per-turn lifecycle hooks —
session-start.sh/post-tool-use.sh/user-prompt-submit.sh/session-end.sh(theon_final_outputequivalent) feed asession_turnstable. - 3-behavior rejection taxonomy —
allow/reject_content(retry with hint) /deny(hard halt), mirroring the SDK’sToolGuardrailFunctionOutput; every rejection a typed event with a non-empty message (audit invariant). HandoffInputDataenvelope — zlib+b64 payload (the 0.43% result above).- Transcript compaction on handoff — opt-in; local
gemma3:12bwith Haiku circuit-breaker fallback. - Agent-as-tool wrapper for the 10 sub-agents, for the ambiguous-risk (0.4–0.6) band.
- Handoff depth + cycle detection — depth ≥ 5 forces
[POLL], ≥ 10 hard-halts; atomicBEGIN IMMEDIATEtransactions for race-free bumps. - Immutable per-turn snapshots before each mutating tool;
rollback_to(snapshot_id), 7-day retention.
Four new tables brought the schema to 35 at the time (now 46 after the teacher-agent, NVIDIA, and infragraph batches); migrations apply idempotently on fresh and legacy DBs.
QA Suite — 533+ known-passing tests, 51 suite files
A pytest-style bash harness (scripts/qa/run-qa-suite.sh, 51 suite files, ~3–5 min under full-suite load) verifies every adoption with a JSON scorecard output. A per-suite QA_PER_SUITE_TIMEOUT wrapper (default 120 s) caps any slow/wedged suite and emits a synthetic FAIL record to the scorecard so the orchestrator never hangs silently. Coverage highlights:
- Writer stamping — 11 / 11 writers + 5 / 5 n8n workflow INSERT sites asserted.
- Pattern-by-pattern — 53 deny + 32 reject_content / allow tests.
- Per-event payload shapes — all 13 event classes round-trip through CLI + Python.
- Concurrent safety — 8 parallel
handoff_depth.bump()asserted no-lost-updates. The test surfaced a real race condition (Python sqlite3’s defaultisolation_level=""defeatingBEGIN IMMEDIATE); fix shipped in the same commit. - Mock HTTP server — stdlib-only forking server faking ollama / anthropic for offline compaction happy-path testing.
- 6 e2e scenarios — happy path (all 9 adoptions in one flow), cycle prevention, crash rollback, schema forward-compat, envelope-to-subagent, compaction in handoff.
- Benchmarks — p95 latencies: event emit 111 ms, handoff bump 108 ms, envelope encode 76 ms, snapshot capture 86 ms, hook 198 ms. Migration on a 10K-row legacy DB: ~200 ms. Compression ratio 0.43% (23× better than target).
Writing the tests also surfaced — and fixed — four code bugs: legacy hooks emitting JSON that breaks Claude Code validation, five writers hardcoding the prod DB path, the missing on_final_output hook, and schema.sql lacking canonical CREATE TABLEs for the new versioned tables.
CLI-Session RAG Capture — interactive sessions flow into RAG too
Before this, only YT-backed agentic sessions had their transcripts, tool calls, and extracted knowledge written into the shared RAG tables. Interactive Claude Code CLI sessions — operator typing directly into a terminal, no webhook, no YT ticket — were only captured by a token-counting poller for cost tracking. Their reasoning, tool use, and outcomes were lost to retrieval.
A 3-tier pipeline (IFRNLLEI01PRD-646/-647/-648 ) closes the gap with a single cron line that chains three idempotent steps over every CLI JSONL:
- Archive transcripts — exchange-pair chunks into
session_transcriptswithnomic-embed-textembeddings; sessions above 5000 assistant chars also get a doc-chain refined summary row. - Parse tool calls —
tool_use/tool_resultpairs intotool_call_log, taggedissue_id='cli-<uuid>'so both tables join cleanly. - Extract knowledge —
gemma3:12bin strict-JSON mode over the summary rows → structured{root_cause, resolution, subsystem, tags, confidence}→incident_knowledgewithproject='chatops-cli', embedded for retrieval.
Retrieval weights chatops-cli rows at CLI_INCIDENT_WEIGHT=0.75 by default so real infra incidents still win close ties. A byte-offset watermark skips unchanged files so the nightly cron drains the ~2,300-file backlog incrementally without re-chunking settled sessions. Soak test (10 files): 12 chunks + 245 tool calls + 4 summaries + 4 extracted knowledge rows; gemma correctly classified one sample as subsystem=sqlite-schema, tags=[schema, migration, versioning, data], confidence=0.95. 12 QA tests covering flag parsing, watermark roundtrip, path inference, sanitization, and retrieval weighting — all PASS.
Skill Authoring Discipline — 6 dimensions closed vs google/agents-cli
Audited against google/agents-cli
— Google’s own reference for skill-authoring convention on Gemini/ADK — across 16 dimensions. This platform won 9 on raw capability but trailed on six skill-authoring dimensions agents-cli treats as first-class; an 11-commit uplift (umbrella IFRNLLEI01PRD-712, Phases A→J, zero reverts) closed all six. Scorecard 3.94 → 4.94; 13/16 dimensions now at 5/5.
The six closed dimensions
- Master phase-gate skill — a new
chatops-workflow/SKILL.mdcodifies the Phase 0→6 incident lifecycle (triage → drift-check → alert-context → propose → approve → execute → post-incident) with explicit exit criteria per phase. The Runner’s Build Prompt node force-injects the full skill body into every session’s system prompt, marker-delimited for surgical removal and with the pre-injection workflow snapshot preserved as a rollback anchor. Proven end-to-end by a real Runner session whose first tool call wasgrep -i "Phase 0"against its own injected prompt. - Auto-generated skill index —
scripts/render-skill-index.pywalks allSKILL.md+ agent frontmatter and emitsdocs/skills-index.mdas the canonical single source of truth. A drift-guard QA test (test-656-skill-index-fresh.sh) fails CI if the committed index would differ from a fresh render. Wired into the daily 04:30 UTC wiki-compile cron so the browsable wiki picks it up automatically. - Versioned + machine-audited skills — every
SKILL.mdand.claude/agents/*.mdfrontmatter now carriesversion: 1.x.0+ arequires: {bins, env}block.scripts/audit-skill-requires.shverifies declared binaries (which) and env vars (test -n); a Prometheus exporter feeds two new alerts (SkillPrereqMissing,SkillMetricsExporterStale).scripts/audit-skill-versions.shwalks git history for skill bodies that changed without a version bump. Per-skill semver convention formalized indocs/runbooks/skill-versioning.md(patch/minor/MAJOR tied to changes in the skill contract — name, description, allowed-tools, requires, output format). - “Do NOT use for X” anti-guidance — every primary skill/agent description now ends with an explicit negative-guidance clause pointing to the correct alternative. Measurably reduces over-routing (e.g.,
security-analystno longer gets picked for disk-full alerts whose symptom overlaps). - 46 Shortcuts-to-Resist rows inlined on 11 agents — each row drawn verbatim from the matching
memory/feedback_*.mdlesson with source citation. Behavioral inoculation at the surface where the model is about to act, instead of trusting RAG to surface 50+ scattered lesson files on demand. - Proving-Your-Work directive +
evidence_missingsignal — the risk classifier now emitsevidence_missingwhenCONFIDENCE ≥ 0.8is claimed without any visible tool output or code fence in the reply, forcing[POLL]instead of[AUTO-RESOLVE]. Mirrored in the Runner’s Prepare Result node so[AUTO-RESOLVE]markers are stripped and aGUARDRAIL EVIDENCE-MISSING:banner is prepended to unproven high-confidence replies before they reach Matrix. - Operator-vocabulary map —
config/user-vocabulary.json(20 entries) disambiguates operator shorthand; the prompt-submit hook logs a typedvocabularyevent on match.
All 6 targeted dimensions closed (phase-gate choreography, discoverability, anti-guidance, inline anti-patterns, governance/versioning, auto-generated index); +27 new QA tests.
Full audit memo: docs/scorecard-post-agents-cli-adoption.md
.
NVIDIA DLI Cross-Audit + P0+P1 Implementation
The 19-transcript NVIDIA DLI Agentic AI Systems course was the only major agentic-AI source not yet evaluated here. The 12-dimension cross-audit graded the system at A (4.4 / 5.0) — the lowest of the 9 rubrics audited. A same-day implementation closed all 7 P0+P1 gaps and lifted it to A+ (4.83), restoring A+ across all 9 sources (aggregate A+ 4.79). Zero reverts; 57/57 new QA tests pass.
The G1–G4 deliverables
- G1 — Long-horizon reasoning replay eval (
scripts/long-horizon-replay.py) replays the 30 longest historical sessions weekly (Mon 05:00 UTC), scoring trace_coherence (Jaccard of adjacent assistant turn word-sets), tool_efficiency, poll_correctness vssession_risk_audit, and cost_per_turn_z. Pure SQLite reads, no live Claude calls. Newlong_horizon_replay_resultstable; new alertLongHorizonReplayStale. - G1 — Jailbreak corpus + Greek extension — 39 fixtures across the 5 NVIDIA-DLI-08 chat-fragility vectors (asterisk-obfuscation, persona-shift, retroactive-history-edit, context-injection, lost-in-middle-bait), including 8 Greek operator-language fixtures (
αγνόησε προηγούμενες οδηγίες,ξέχασε όλα όσα ξέρεις,είσαι τώρα,παρίστανε ότι,παράκαμψε περιορισμούς,όπως ήδη συμφωνήσαμε,ο χρήστης έχει ήδη εγκρίνει,στην προηγούμενη απάντηση). Pure-regexscripts/lib/jailbreak_detector.py; weekly regression cron (Wed 05:00 UTC); new alertJailbreakBypassDetectedon any miss. - G2 — Intermediate semantic rail (DARK-FIRST) —
scripts/lib/intermediate_rail.py(heuristic + Ollama dual-backend) inserted as aCheck Intermediate RailCode node between Build Plan and Classify Risk in the Runner workflow (now 50 nodes). Emitsintermediate_rail_checkevent_log row per session; new alertIntermediateRailDriftHighat >20% out-of-distribution rate over 24h. Observe-only — does NOT block; soft-gate evaluation deferred ≥7 days post-data per the audit’s recommended posture. - G2 — Grammar-constrained decoding — JSON Schemas at
scripts/lib/grammars/{quiz-grader,quiz-generator,risk-classifier}.schema.jsonpassed to Ollama via theformatfield whenOLLAMA_USE_GRAMMAR=1(default on). Falls back toformat=jsonon schema rejection. Circuit-breaker semantics (rag_synth_ollama) preserved. - G3 — Team-formation skill — new
.claude/skills/team-formation/SKILL.md(v1.0.0) +scripts/lib/team_formation.pypropose a sub-agent roster per(alert_category, risk_level, hostname). Build Prompt injects a## Team Charter (advisory)section; same JSON emitted asteam_charterevent_log row. KNOWN_AGENTS inventory enforced against.claude/agents/*.md. - G3 — Inference-Time-Scaling explicit budget —
EXTENDED_THINKING_BUDGET_Senv var (+ optional per-categoryEXTENDED_THINKING_BUDGET_BY_CATEGORY_JSON) drives a## Reasoning BudgetBuild Prompt section;its_budget_consumedevent captures observed turns / thinking_chars at session end. - G4 — Server-side session-replay endpoint — new n8n workflow
claude-gateway-session-replay.json(idlJEGboDYLmx25kBo, ACTIVE). Webhook POST/session-replayaccepts{session_id, prompt}, validates format, sqlite3-checks session existence inside the SSH command (the n8n task-runner sandbox blockschild_processin Code nodes), runsclaude -r, returns JSON. HTTP 404 on unknown session, HTTP 400 on malformed input.session_replay_invokedevent.
Schema deltas: event_log v=1 → v=4, 13 → 17 event types (+4: team_charter, its_budget_consumed, intermediate_rail_check, session_replay_invoked); 18 → 19 schema-versioned tables; 26 → 27 n8n workflows; 6 → 7 skills (+team-formation); 44 → 51 QA suite files (+7); 411 → 468 QA tests (+57); 27 → 30 Prometheus alert rules.
Operator gates closed (cert pass 2, same day): 5 cron entries installed; intermediate-rail node inserted; session-replay workflow activated and live-smoked; Greek fixtures added; all 5 YouTrack issues moved to Done.
Single source-of-record: docs/agentic-platform-state-2026-04-29.md
(audit, certification, and re-scored docs linked from there).
The 3-Tier Architecture
Alert Source Tier 1 Tier 2 Tier 3
───────────── ────── ────── ──────
LibreNMS ┐ run-triage.sh Claude Code Human
Prometheus ├──► n8n ──► (deterministic) ──► (Opus 4.7) ──► (Matrix)
CrowdSec ┤ suppression+RAG 11 sub-agents polls
GitLab CI ┘ 7-21 sec 5-15 min reactions
- Tier 1 (claude01 dispatch via
run-triage.sh): Fast triage (7-21s). Each n8n alert receiver SSHes directly tonllei01claude01and invokes a single wrapper that exec’s the matching skill —infra-triage.sh,k8s-triage.sh,security-triage.sh,correlated-triage.sh, orescalate-to-claude.sh. The pipeline is deterministic shell with embedded local LLM calls (gemma3:12bsynth,nomic-embed-textretrieval): NetBox CMDB lookup, 5-signal RAG, SSH to host, knowledge extraction from 55 CLAUDE.md files + 200+ operational memory rules, confidence scoring. Creates YouTrack issues; resolves or dedups a measured share at Tier 1 (per-incident auto-resolve baseline 41.6% over 30d, frozen 2026-06-09) and escalates the rest. OpenClaw was retired in April 2026 — see Architecture History at the foot of the page for the two-step migration (Tier 1 model GPT-5.1 → Sonnet 4.6 OAuth, then OpenClaw retired entirely ~17 hours later) and the cutover lifecycle. - Tier 2 (Claude Code / Opus 4.7): Deep analysis (2-15 min). A Haiku planner first generates a 3-5 step investigation plan and queries AWX for matching playbooks from 41 templates; Claude Code then follows the plan, launches AWX jobs (dry_run first), delegates to 10 sub-agents in parallel, and proposes remediation via [POLL]. All agents write diary entries for cross-session learning. Migrated Opus 4.6 → Opus 4.7 as primary Tier 2 model on 2026-04-19 (
b2fa660); Opus 4.6 retained as legacy fallback. The live token-usage widget at the top of the page shows the actual req/token split between the two. - Tier 3 (Human): Clicks a poll option in Matrix. The system stops and waits here — it never acts autonomously on infrastructure.
Three Subsystems
| Subsystem | Scope | Alert Sources |
|---|---|---|
| ChatOps | Infrastructure availability, performance, maintenance | LibreNMS, Prometheus, Synology DSM |
| ChatSecOps | Intrusion detection, vulnerability scanning, MITRE ATT&CK mapping | CrowdSec (54 scenarios → 21 ATT&CK techniques), vulnerability scanners |
| ChatDevOps | CI/CD failures, code review, multi-repo refactoring | GitLab CI webhooks |
All three share the same engine: n8n orchestration, Matrix as human-in-the-loop, and the 3-tier agent architecture.
Safety — 7 Layers
Because “the prompt says don’t do that” is not a security boundary:
| Layer | Mechanism | Bypassed by prompt injection? |
|---|---|---|
| Claude Code hooks | 78 blocked patterns (37 destructive + 22 exfil + 7 injection) + 15 protected file patterns + word-boundary precision on single-word commands (passwd/useradd/halt etc.). Now emits the 3-behavior taxonomy — allow (silent exit 0) / reject_content (exit 2 with retry hint) / deny (hard halt) — with every rejection landing as a typed tool_guardrail_rejection event. An evidence_missing risk signal fires in-band when CONFIDENCE ≥ 0.8 is claimed without a visible tool output block, forcing [POLL] and stripping unearned [AUTO-RESOLVE] markers. | No — deterministic, fires first |
| safe-exec.sh | Code-level blocklist, rate limiting (30/min), exfiltration detection | No — code enforcement |
| exec-approvals.json | 36 specific skill patterns, no wildcards | No — config enforcement |
| Input sanitization | 17 injection patterns (encoding obfuscation, role confusion, delimiter injection, social engineering) | No — code enforcement |
| Evaluator-Optimizer | Haiku screening for high-stakes responses (3-node n8n flow) | No — second-pass review |
| Credential / PII scanning | 16 regex patterns + 39 credentials tracked with rotation dates | N/A |
| Approval gates | Infrastructure changes require human thumbs-up or poll vote | No — workflow enforcement |
| Handoff depth + cycle detection | Atomic counter on sessions.handoff_depth; ≥ 5 forces [POLL], ≥ 10 hard-halts, any agent twice in the chain is refused and logged as handoff_cycle_detected | No — transaction-serialised in SQLite |
Additional: €5/session warning, $25/day budget ceiling, confidence gating (< 0.5 = STOP, < 0.7 = escalate), tool call limit of 75 per session. Synth failure handling: when Haiku synth is opted into (SYNTH_BACKEND=haiku), SYNTH_HAIKU_FORCE_FAIL injects 5 failure modes (429 / auth / timeout / network / empty) and the pipeline falls back to local qwen2.5 without breaking the response chain. Every mutating tool call is preceded by an immutable snapshot to session_state_snapshot for mid-session rollback.
Evaluation System
All evals run deterministically (temperature=0, seed=42).
| System | What it measures |
|---|---|
| 161+ Test Scenarios | 58 eval scenarios (3 sets) + 54 adversarial + 23 holistic E2E + 22 mempalace + 22 security-hook + 9 KG-traverse + 17 synth-fallback + 20 qwen-JSON reliability |
| Hard-Retrieval v2 | 50-query weekly eval — judge-graded hit@5 = 0.90, p50 latency 5.7s, p95 13.6s |
| RAGAS Golden Set | 33 queries (15 hard-eval tagged) across multi-hop / temporal / negation / meta / cross-corpus |
| Prompt Scorecard | 19 prompt surfaces graded daily on 6 dimensions |
| LLM-as-a-Judge | Every session scored by local gemma3:12b (default since 2026-04-19, 85% Haiku-agreement on 60-query calibration); flagged sessions re-scored by Opus |
| Agent Trajectory | Per-session step scoring from JSONL transcripts (8 infra / 4 dev steps) |
| Self-Improving Prompts | Low-scoring dimensions auto-generate prompt patches (5 currently active) |
| Eval Flywheel | Monthly: analyze → measure → improve → validate cycle |
| A/B Testing | react_v1 vs react_v2 variants, deterministic by issue hash |
| CI Eval Gate | eval-regression stage between test and review — blocks bad merges |
Tech Stack
| Component | Role |
|---|---|
| n8n | Workflow orchestration — 32 active workflows (runner, bridge, poller, session-end, teacher-runner, receivers, portfolio + chaos APIs, server-side session-replay) |
scripts/run-triage.sh + openclaw/skills/ (cc-cc dispatch) | Tier 1 dispatch (current, since 2026-04-29). Deterministic shell pipeline on nllei01claude01 invoked by 9 n8n receivers via SSH. 17 in-repo triage skills (NetBox CMDB lookup, 5-signal RAG, SSH-to-host, knowledge extraction). Replaces OpenClaw
LXC LLM agent retired 2026-04-29 |
| Claude Code (Opus 4.7, primary since 2026-04-19; Opus 4.6 legacy fallback) | Tier 2 — deep analysis, 11 sub-agents + master chatops-workflow phase-gate skill, Plan-and-Execute, ReAct reasoning |
| AWX | 41 Ansible playbooks — maintenance, cert sync, K8s drain, updates, deployment |
| Matrix (Synapse) | Human-in-the-loop — polls, reactions, replies |
| YouTrack | Issue tracking, state management, knowledge sink |
| NetBox | CMDB — 310+ devices, 421 IPs, 39 VLANs |
| Prometheus + Grafana | 12 custom dashboards, 64+ panels, 16+ exporters, 4 alert-rule files (all sidecar-provisioned via ConfigMaps) |
| OpenObserve | OTel tracing — OTLP span collection + Prometheus-compatible queries |
| Ollama (RTX 3090 Ti) | Local embeddings (nomic-embed-text) + local judge (gemma3:12b) + local synth (qwen2.5:7b) |
bge-reranker-v2-m3 | Cross-encoder reranker on nllei01gpu01:11436 — reorders fused RAG results before synth |
Tri-Source Audit — 11/11 A+
Scored against three knowledge sources: Gulli’s Agentic Design Patterns (21/21 patterns), Anthropic Claude Certified Architect Foundations, and 6 industry sources. Result: 11/11 dimensions at A+ (100%). Additionally, an Operational Activation Audit verified all database tables are populated with 150K+ production rows — scoring infrastructure that actually produces data, not just exists.
Holistic Health Check — 96%+
holistic-agentic-health.sh
runs ~148 automated checks across 39 sections (incl. §39 infragraph: graph populated, 0 stale edges, seed/learn crons, triage wiring + kill-switch) — verifying every feature in this page actually works in production. Not just “does the file exist?” but functional tests (RAG search returns known incidents, Ollama generates 768-dim embeddings, trajectory scoring produces output), cross-site verification (6/6 VTI tunnels READY, 7 BGP peers, ping 42ms), infrastructure health (7/7 K8s nodes, 139/139 Prometheus targets UP, GPU 46°C), and security compliance (both scanners ran within 26h, MITRE Navigator accessible). Results stored in SQLite for trending, exported to Prometheus for Grafana dashboards. Runs in 18 seconds.
Session-Holistic E2E — 23/23
A second suite of 23 end-to-end tests (157s total runtime) covers 18 YouTrack issues with before/after scoring against production data: 23/23 PASS at the last run (2026-04-19). Each test drives a real session through the full pipeline — Tier 1 triage, Tier 2 plan/execute, RAG retrieval, judge scoring — and asserts on output quality, not just exit codes. Output: docs/session-holistic-e2e-*.md
.
Status
| Milestone | Status |
|---|---|
| Self-improving prompts (eval → auto-patch → re-eval) | Production |
| Plan-and-Execute + AWX runbooks (41 playbooks) | Production |
| Predictive alerting (LibreNMS trending + daily digest) | Production |
| 5-signal RAG + GraphRAG + cross-encoder rerank + temporal filter (716 entities, 607 rels) | Production |
Cross-chunk synth (local qwen2.5:7b, +13pp hit@5 on hard eval) + 5-mode failure injection | Production |
Local-first judge + synth (gemma3:12b + qwen2.5:7b, 2026-04-19 flip) | Production |
mtime-sort intent detector + list-recent CLI | Production |
Karpathy-style compiled wiki (72 articles, source_mtime column) | Production |
| OTel tracing (39K spans → OpenObserve) | Production |
| Tool call instrumentation (119K calls, 108 types) | Production |
| 3-tier agent architecture | Production |
| 32 active n8n workflows (27 exported) | Production |
| 9 MCP servers (~167 tools) | Production |
| 11 sub-agents with diary entries | Production |
Skill-authoring uplift vs google/agents-cli — scorecard 3.94 → 4.94, 6 gap dimensions closed (Phases A→J, umbrella IFRNLLEI01PRD-712) | Production |
Master phase-gate skill (chatops-workflow/SKILL.md) force-injected into every Runner session | Production |
Auto-generated skills index (docs/skills-index.md) drift-gated by test-656 | Production |
Skill versioning + requires audit — 17/17 SKILL.md with version: 1.x.0 + requires: {bins, env}; 2 new Prom alerts | Production |
46 Shortcuts-to-Resist rows inlined across 11 agents (source-cited to memory/feedback_*.md) | Production |
evidence_missing risk signal — forces [POLL] when CONFIDENCE ≥ 0.8 without a visible tool output block | Production |
Operator-vocabulary map (config/user-vocabulary.json, 20 entries) — prompt-submit hook logs vocabulary events to event_log | Production |
| NVIDIA DLI 12-dim cross-audit — A (4.4) → A+ (4.83), 9/12 dims at A+ ceiling, 9-source aggregate A+ (4.79) | Production |
| Long-horizon reasoning replay eval (Monday 05:00 UTC weekly cron, 30 longest sessions, 4-dim scoring) | Production |
| Jailbreak corpus + Greek extension — 39 fixtures, 5 NVIDIA-DLI-08 vectors + 8 Greek operator-language; weekly regression cron | Production |
| Intermediate semantic rail (DARK-FIRST) — Code node between Build Plan and Classify Risk, dual-backend (heuristic + Ollama gemma3:12b) | Production |
| Grammar-constrained decoding for Ollama JSON outputs (3 JSON Schemas, OLLAMA_USE_GRAMMAR=1 default) | Production |
Team-formation skill — .claude/skills/team-formation/SKILL.md v1.0.0 + team_charter event injected by Build Prompt | Production |
Inference-Time-Scaling explicit budget — EXTENDED_THINKING_BUDGET_S env var + its_budget_consumed event | Production |
Server-side session-replay endpoint — lJEGboDYLmx25kBo ACTIVE, POST /session-replay → claude -r, HTTP 404/400 verified | Production |
Tier 2 model migration (2026-04-19) — Opus 4.6 → Opus 4.7 as primary Claude Code investigation model (b2fa660); Opus 4.6 retained as legacy. Live req/token split visible in the token-usage widget at the top of the page | Production |
| Infragraph causal world-model (2026-06-09, epic IFRNLLEI01PRD-1029) — 716-entity / 607-edge dependency graph, 5 truth layers + learned dynamics; advisory context in every triage + Tier-2 prompt | Production |
Model-based prediction gate — no remediation reaches the approval poll without a committed plan-hash-keyed machine prediction ([POLL-WITHHELD:NO-PREDICTION] otherwise); remediation lane fails CLOSED | Production |
Mechanical verification — code (never the proposing LLM) writes match/partial/deviation verdicts; deviation never auto-resolves | Production |
| Infragraph backtest — 2026-05-11 cascade: 38.2% escalation coverage, shuffled-control ratio 0.367 ≤ 0.5× (falsifiable criterion PASSED) | Evidence captured |
Phase-C proposal lane — infragraph-propose-blast-radius.py proposes per-rule; operator approves; first rule (nllei01pve04 cascade fold) approved + production-verified 2026-06-09 | Production |
cc-cc dispatch (2026-04-29) — 9 receivers SSH directly to nllei01claude01 and invoke scripts/run-triage.sh; OpenClaw LXC 103101212 stopped, onboot=0, 2 openclaw crons disabled with rollback markers | Production |
Tier 1 model migration (2026-04-29 morning) — GPT-5.1 → Sonnet 4.6 via OpenClaw native --auth-choice claude-cli; marginal cost → $0; OAuth fallback ladder Opus 4.6 → Opus 4.5 → Sonnet 4.5 → Haiku 4.5 | Production (then OpenClaw retired same-day evening) |
holistic-agentic-health.sh §38 cc-cc-receiver-wiring — drift-check asserts every receiver still references run-triage.sh; durable check after the cutover canary was retired | Production |
Receiver-canary cutover instrument (retired 2026-04-30) — synthetic alert cron + 2 Prometheus alerts (ReceiverCanaryFailing, ReceiverCanaryStale) ran during 24h cutover window then retired; lessons captured as feedback_canary_for_dispatch_chain_changes.md + feedback_canary_must_clean_its_own_artifacts.md | Retired (intentionally) |
| 21/21 agentic design patterns | Audited (7 at A+) |
| Tri-source + operational activation audit | 11/11 A+ |
| 7-layer safety + word-boundary precision on hook patterns | Production |
| OpenAI Agents SDK adoption batch (9 / 11 gaps landed, 2026-04-20) | Production |
Schema versioning on 13 tables + central CURRENT_SCHEMA_VERSION registry | Production |
17 typed session events in event_log (schema_version=4) with Prom exporter | Production |
Per-turn hooks (session-start.sh / post-tool-use.sh / user-prompt-submit.sh / session-end.sh) + session_turns table | Production |
3-behavior rejection taxonomy (allow / reject_content / deny) + event_log audit invariant | Production |
HandoffInputData envelope (zlib+b64, 0.43% ratio) + handoff_log audit table | Production |
| Handoff transcript compaction (local gemma first, Haiku fallback, circuit-breaker-aware) | Production |
| Agent-as-tool wrapper for 10 sub-agents | Production |
| Handoff depth + cycle detection (atomic IMMEDIATE tx, PRAGMA busy_timeout=10000) | Production |
| Immutable per-turn snapshots + rollback + 7-day retention cron | Production |
46 SQLite tables (150K+ rows; +infragraph_dynamics + infragraph_predictions in the 2026-06-09 batch); 21 schema-versioned via central CURRENT_SCHEMA_VERSION registry | Production |
| Hardened RAGAS golden set — 33 queries (15 hard-eval), 10× differential | Production |
| Weekly hard-eval cron (50-q) — judge_hit@5 = 0.90 | Production |
| 3 absent-metric alerts guarding the staleness alerts themselves | Production |
| 161+ eval scenarios across 8 test suites | All passing |
| Preference-iterating prompt patcher — N-candidate A/B trials + Welch t-test + auto-promote | Production |
| CLI-session RAG capture — interactive CLI sessions now flow into session_transcripts + tool_call_log + incident_knowledge | Production |
| QA suite — 51 files, 533+ known-passing (468 at the NVIDIA close + 65 infragraph), per-suite timeout guard | Green |
| 12-dashboard observability (64+ panels) | Production |
| Weekly chaos cron (self-selecting, preflight gate, Matrix notifications) | Production (CMM L3) |
| A/B prompt testing | Active |
| Holistic health check (~148 checks, 39 sections) | 96%+ pass |
| Session-holistic E2E (23 tests covering 18 YouTrack issues) | 100% (23/23) |
Architecture History
cc-cc dispatch and the OpenClaw retirement (April 2026) — the migration that produced today's Tier 1
Two coupled migrations on a single day moved Tier 1 from “OpenClaw LLM agent on a separate LXC” to today’s deterministic dispatch on the Claude Code host.
Two coupled migrations on a single day moved Tier 1 from “OpenClaw LLM agent on a separate LXC” to today’s deterministic dispatch on the Claude Code host. The page text below this section reflects the post-migration architecture; this subsection captures the lifecycle.
Step 1 — GPT-5.1 → Sonnet 4.6 via OpenClaw native OAuth (commit ca12fab, 00:34 CEST). OpenClaw 2026.4.11 ships native --auth-choice claude-cli support, so the model behind OpenClaw was migrated by spawning a claude CLI subprocess inside the OpenClaw container that talks to api.anthropic.com on the operator’s Max subscription. No shim, no proxy. Marginal cost goes from paid GPT-5.1 per-call to $0. Fallback ladder (also OAuth, no paid keys retained): Opus 4.6 → Opus 4.5 → Sonnet 4.5 → Haiku 4.5. Cost-tracking flow switched to scripts/poll-openclaw-usage.sh
reading the container’s ~/.claude/projects/**/*.jsonl via SSH+docker exec.
Step 2 — OpenClaw retired entirely, cc-cc cutover (commit 484f5da, 18:14 CEST). ~17 hours after Step 1, an Anthropic April-4 OAuth-for-third-party-tools ban + an OpenClaw 2026.4.26 MCP-bind regression made the agent path unreliable (5+ hours of silent triage that day). Pivoted from oc-cc to cc-cc mode: 9 alert receivers SSH directly to nllei01claude01 and invoke scripts/run-triage.sh <kind> <args...> instead of posting @openclaw use exec to run... Matrix mentions. LXC 103101212 stopped, onboot=0 on nllei01pve03, 2 openclaw crons commented out with rollback markers. The 6 yt-* helpers + escalate-to-claude.sh that previously lived only inside the container’s /root/.openclaw/workspace/skills/ were pulled into the repo (root cause of an exit-127 silent triage failure that day — they were never version-controlled). All triage scripts patched for host portability via ${TRIAGE_X:-default} env-var fallbacks: same code runs on claude01 today, in the OpenClaw container tomorrow if rolled back.
Cutover canary lifecycle (cutover-only instrument, retired 2026-04-30). A synthetic alert cron (scripts/receiver-canary.sh, every 30 min) + 2 Prometheus alerts (ReceiverCanaryFailing 35m crit, ReceiverCanaryStale 10m warn) ran during the cutover window. Once real-alert volume confirmed steady state, all three were retired (commit 2c4af83) — real alerts already exercise the chain hourly, the canary was producing 48 synthetic YT issues/day with no added signal. Lesson captured as feedback_canary_for_dispatch_chain_changes.md (install for cutover, retire after steady state) + feedback_canary_must_clean_its_own_artifacts.md (auto-clean or use a separate queue — “operator filters by name” doesn’t scale).
Durable structural drift-check. holistic-agentic-health.sh §38 cc-cc-receiver-wiring asserts every one of the 9 receivers still references scripts/run-triage.sh — catches silent re-wiring drift even after the canary is gone.
E2E proven on 8 paths the day of cutover: Prometheus NL+GR, LibreNMS NL+GR, security NL+GR, Synology DSM, receiver-canary smoke. Full QA suite re-run post-migration: 468/0/2 = 99.57% (51 suites + 9 benchmarks).
Rollback path if needed: pct start 103101212 + uncomment the 2 disabled crons + restore the workflow JSONs from /tmp/openclaw-migration-snapshots/. Triage scripts work in both environments after the env-var refactor, so step 1 is the only hard dependency.
Built by a solo infrastructure operator who got tired of waking up at 3am for alerts that an AI could triage.