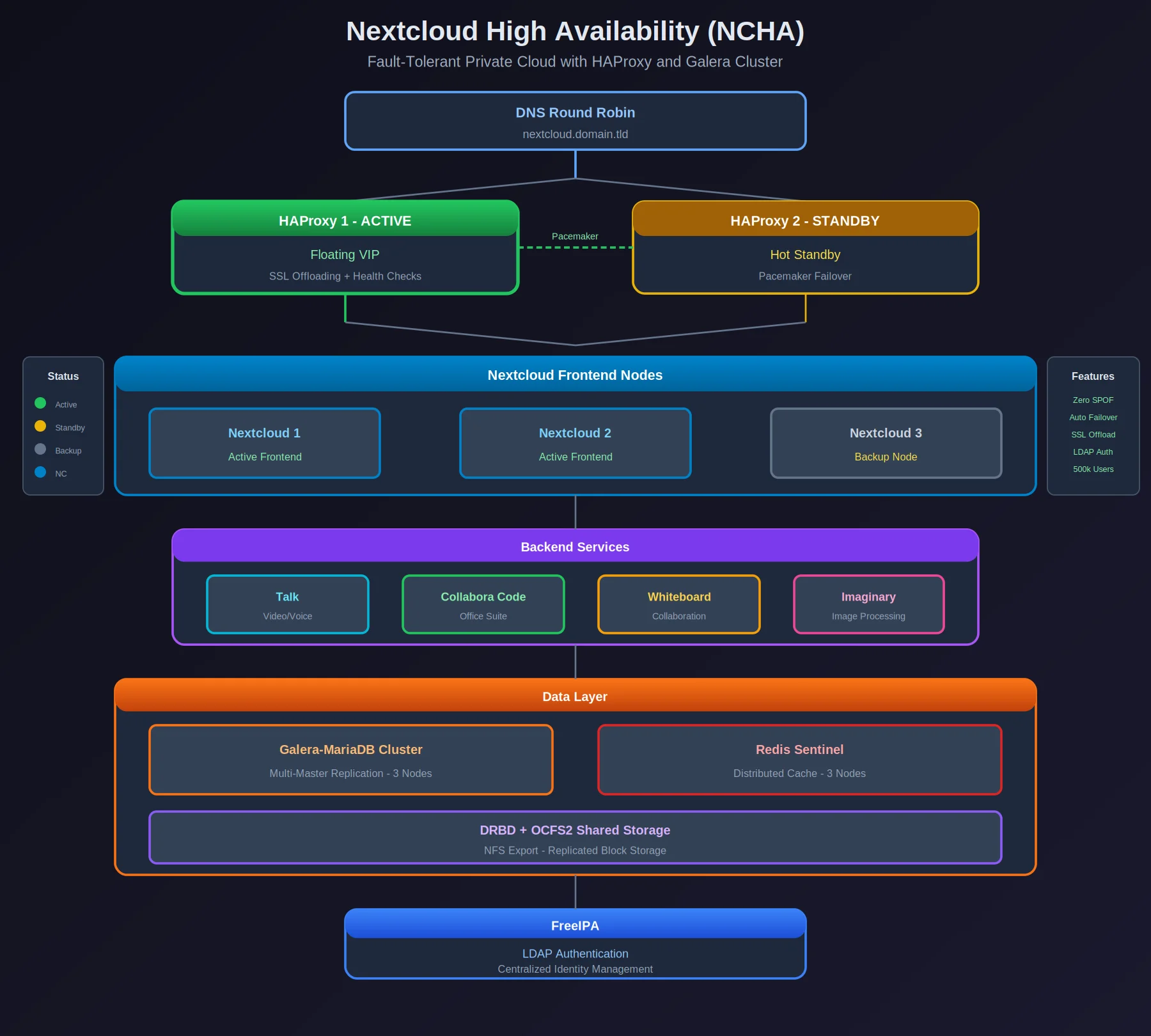
A self-hosted Nextcloud cluster spread across multiple Proxmox nodes, built so that losing a node doesn’t take down file storage, Talk, Collabora, or Whiteboard. Same clustering approach as the HAHA project — Pacemaker, DRBD, the works — applied to a different problem.
Overview
| Aspect | Details |
|---|---|
| Load Balancing | HAProxy (Layer 7) + DNS Round Robin |
| Database | Galera-MariaDB cluster |
| Cache | Redis Sentinel |
| Storage | DRBD + OCFS2 shared volumes |
| Authentication | FreeIPA LDAP |
| Services | Nextcloud, Talk, Collabora Code, Whiteboard |
Technology Stack
Orchestration & HA
- Corosync + Pacemaker for VIP management
- HAProxy for Layer 7 load balancing
- DNS Round Robin for geographic distribution
Storage Backend
- DRBD + OCFS2 shared volumes
- Clustered Galera-MariaDB for database HA
- Redis Sentinel for distributed caching
Networking & Security
- FreeIPA-based LDAP authentication
- SSL offloading at HAProxy
- Health checks for automatic failover
Nextcloud Services
- Frontend nodes (web servers)
- Backend services: Talk, Collabora Code, Imaginary, Whiteboard
- WebDAV for file access
Infrastructure
- Two NVMe-equipped nodes with PCI passthrough
- Third arbitrator node for quorum
Architecture
┌─────────────────────────────────────────────────────────────────┐
│ DNS Round Robin │
│ (nextcloud.domain.tld) │
└───────────────────────────┬─────────────────────────────────────┘
│
┌──────────────────┴──────────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ HAProxy 1 │ │ HAProxy 2 │
│ (Active) │◄───────────────►│ (Standby) │
│ Floating VIP │ Pacemaker │ │
└────────┬────────┘ └────────┬────────┘
│ │
└──────────────────┬────────────────┘
│ Health Checks
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Nextcloud 1 │ │ Nextcloud 2 │ │ Nextcloud 3 │
│ Frontend │ │ Frontend │ │ (Backup) │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└────────────────────┼────────────────────┘
│
┌───────────────────────────┴───────────────────────────┐
│ Backend Services │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │ Talk │ │ Collabora │ │ Whiteboard│ │
│ └───────────┘ └───────────┘ └───────────┘ │
└───────────────────────────────────────────────────────┘
│
┌───────────────────────────┴───────────────────────────┐
│ Data Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Galera-MariaDB │ │ Redis Sentinel │ │
│ │ Cluster │ │ (3 nodes) │ │
│ └─────────────────┘ └─────────────────┘ │
│ ┌─────────────────────────────────────────┐ │
│ │ DRBD + OCFS2 (NFS Export) │ │
│ └─────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────┐
│ FreeIPA │
│ (LDAP Authentication) │
└───────────────────────────────────────────────────────┘
What Made This Tricky
The challenge wasn’t any single component — it was getting Galera, Redis Sentinel, DRBD, OCFS2, and HAProxy to all agree on what “healthy” means at the same time. Each layer has its own idea of quorum, its own failure detection, and its own timeout semantics.
HAProxy health checks needed careful tuning to avoid flapping during Galera donor/desynced states. The DRBD + OCFS2 lock handling issues I’d already dealt with in the HAHA project showed up again here, plus new ones from Nextcloud’s file locking interacting with the clustered filesystem.
FreeIPA LDAP as the auth backend added another dependency — if the LDAP server is down, nobody logs in, regardless of how available everything else is.
The system tolerates node failures and restarts without data loss. I’ve tested it by pulling nodes out mid-operation.
Inspired by Matthias Wobben’s “Guide to Nextcloud Cluster Design” for architectures supporting up to 500k users