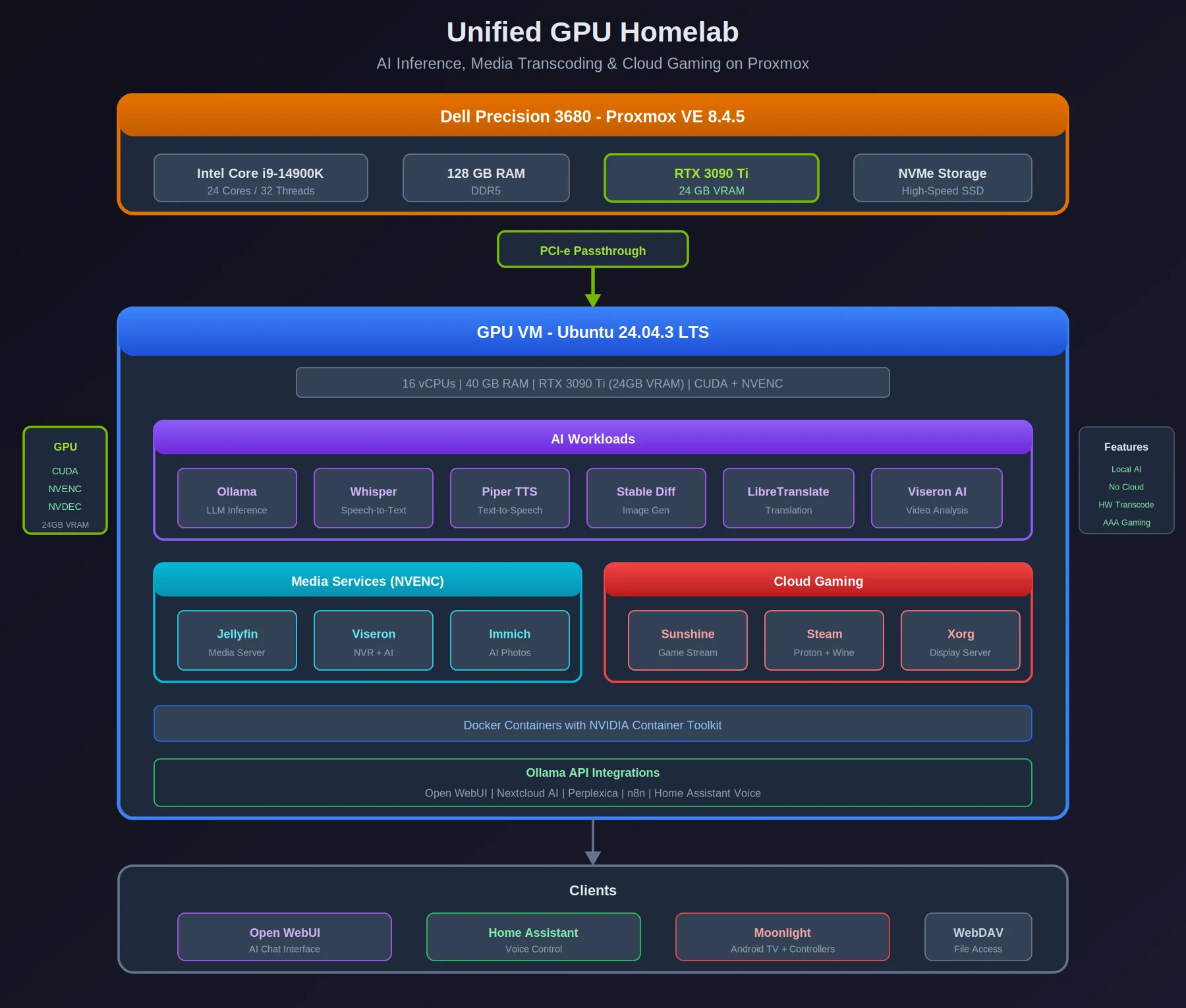
Unified GPU Homelab: AI, Media & Gaming
One Dell Precision 3680 with an RTX 3090 Ti passed through to an Ubuntu VM. It runs local LLMs, transcodes media, and streams PC games — all from the same GPU, depending on what I need at the time. Overview Aspect Details Host Dell Precision 3680 CPU Intel Core i9-14900K RAM 128 GB GPU NVIDIA RTX 3090 Ti (PCI-e passthrough) Hypervisor Proxmox VE 8.4.5 VM 16 vCPUs, 40 GB RAM, Ubuntu 24.04.3 LTS Workload Breakdown AI Inference & Language Tasks Ollama - Local LLM inference Whisper / Faster-Whisper - Speech-to-text Piper TTS - Text-to-speech LibreTranslate - Machine translation Stable Diffusion - Image generation Viseron - AI-powered video analysis Immich - AI-powered photo management Ollama API Integrations Open WebUI (ChatGPT-style interface) Nextcloud AI features Perplexica (AI search) n8n workflow automation Home Assistant voice control Media Streaming & Transcoding Jellyfin - Media server with hardware transcoding Viseron - NVR with AI object detection Immich - Photo/video library with ML features Cloud Gaming Stack Sunshine - Game streaming server Xorg - Display server Steam with Proton + Wine Tested: Cyberpunk 2077 Clients: Moonlight (Android TV), Xbox controllers Architecture ┌─────────────────────────────────────────────────────────────────┐ │ Dell Precision 3680 │ │ i9-14900K | 128 GB RAM │ │ Proxmox VE 8.4.5 │ └─────────────────────────────────────────────────────────────────┘ │ │ PCI-e Passthrough ▼ ┌─────────────────────────────────────────────────────────────────┐ │ GPU VM (Ubuntu 24.04.3) │ │ 16 vCPUs | 40 GB RAM │ │ RTX 3090 Ti (24GB VRAM) │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ AI Workloads │ │ │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ │ │ Ollama │ │ Whisper │ │ Piper │ │ Stable │ │ │ │ │ │ LLM │ │ STT │ │ TTS │ │Diffusion │ │ │ │ │ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ Media Services │ │ │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ │ │ Jellyfin │ │ Viseron │ │ Immich │ │ │ │ │ │ (NVENC) │ │ (NVR) │ │ (Photos) │ │ │ │ │ └──────────┘ └──────────┘ └──────────┘ │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ Cloud Gaming │ │ │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ │ │ Sunshine │ │ Steam │ │ Xorg │ │ │ │ │ │(Streamer)│ │ (Proton) │ │(Display) │ │ │ │ │ └──────────┘ └──────────┘ └──────────┘ │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────┘ │ │ Network ▼ ┌─────────────────────────────────────────────────────────────────┐ │ Clients │ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │ │ Open WebUI │ │Home Assistant│ │ Moonlight │ │ │ │ (AI Chat) │ │(Voice Control)│ │(Game Stream) │ │ │ └──────────────┘ └──────────────┘ └──────────────┘ │ └─────────────────────────────────────────────────────────────────┘ What It Does The GPU is shared across three types of work: ...
